Controller Cluster Deployment Across Two Availability Zones
The Avi Controller is deployed as a three-node cluster for high availability and scalability. These nodes must be deployed such that the RTT (round-trip time) value between two Controller nodes is less than 20 milliseconds. In public cloud deployments such as AWS, a region has multiple availability zones (AZ). In such deployments, as a best practice, each Controller node should be deployed in a separate AZ. Where the region has three or more AZs, Controller cluster deployment considerations are straightforward. However, in many disaster-recovery (DR) deployments, there are only two AZ across which the three Controller cluster nodes are deployed, as depicted below. This document addresses such a deployment, what happens during failures, and the recovery actions needed for certain failures.
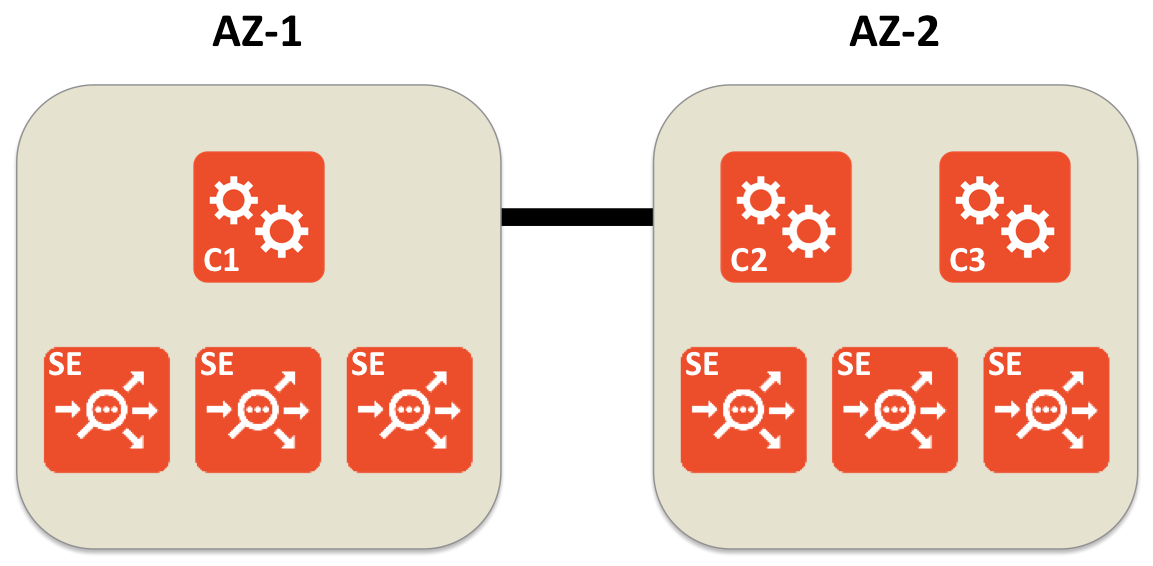
In partition scenarios, the Controller cluster will be up if at least two nodes are up and have connectivity to each other. SEs will attempt to connect to the active partition. If they are unable to connect to the active partition, they will operate without a Controller (in “headless” fashion) and continue to serve application traffic. In the above deployment, if AZ-2 goes down, C1 will be brought down due to a lack of quorum. In such a scenario, a manual intervention is needed to bring the Controller cluster up. At a high level, the manual workflow provides a way to recover the remaining node as a stand-alone cluster and permit two new nodes to be added when appropriate. The procedure is intentionally kept manual to explicitly force the user to recover the partitions carefully.
Recover a Non-Operational Cluster
Log in to the Controller C1 and run the /opt/avi/scripts/recover_cluster.py script. It will re-configure C1 as a standalone cluster, preserve the configuration and analytics data (logs and metrics), and bring the Controller cluster up. Secure channel credentials for the other two Controller nodes will be revoked. SEs having connectivity with C1 will be brought up. As part of this, SEs will reconfigure themselves to connect only to C1.
What Happens When AZ-2 is Recovered
C2 and C3 will be able to form a Cluster. SEs in AZ-2 may connect to either of the two partitions (C1 or C2+C3). At this time, both the partitions are active, which may cause disruption if they run for too long. To prevent this, each Controller node monitors other Controller nodes that are in its configured members list. If a node identifies that it is not present in the configured members list of the other node, it will bring itself down for manual recovery. In this case, both C2 and C3 will detect that C1 has moved forward with manual recovery and will bring themselves down.
Secure channel credentials for all SEs will be revoked. SEs that connect to C2 or C3 during this time will detect that the Controller cluster is in manual recovery state; they will reboot themselves to no longer serve any application traffic. Once an SE comes up, it will try to connect to C1 to establish normal operations. REST API commands sent to the Controllers, C2 and C3, will fail with a status code of 520, indicating that these nodes must be reset to factory defaults using the clean_cluster.py script.
Clean a Non-Operational Cluster
It is assumed that C2 and C3 will be brought down soon after AZ-2 becomes operational. Log in to C2 and C3 and run the script, /opt/avi/scripts/clean_cluster.py. This script will wipe out all the configuration and analytics and bring it up as a standalone node. Once C2 and C3 are cleaned, they can be joined back to C1 to form a three-node cluster.