Kubernetes Service Discovery Definition
Kubernetes is a platform for container orchestration that consists of a group of well-documented, API-oriented fast binaries that are simple foundations for building applications. A Pod is a basic Kubernetes building block. This Kubernetes resource represents a collection of containers that users can create and destroy as needed.
Any internal IP addresses assigned to a Pod can change over time because the Kubernetes cluster scheduler can move or reschedule Pods to other Kubernetes cluster nodes. This presents a new problem: when a Pod moves to a new node, the connection based on its internal IP address stops working, and so it can no longer be used to access the application.
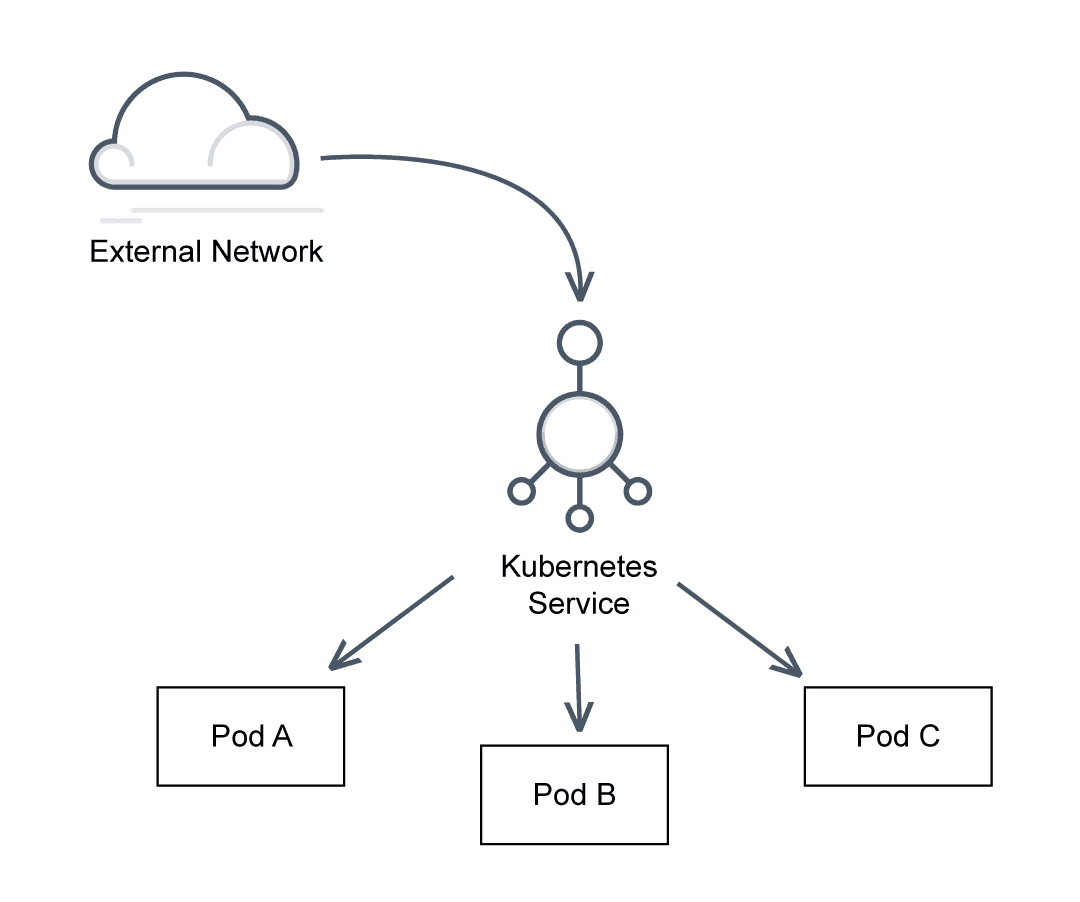
A new layer of abstraction called a Service Deployment allows Pods to remain accessible via other Kubernetes clusters or external networks without relying on internal IPs. Kubernetes service meshes further reduce the challenges presented by service and container sprawl in a microservices environment by automating and standardizing communication between services.
Services allow Pods that work uniformly in clusters to connect across the network. Service discovery is the process of connecting pods and services.
There are two options for discovering services internal to Kubernetes:
- DNS discovery: Kubernetes provides a CoreDNS server and kube-DNS as an add-on resource, and every service registers with the DNS server so they can interact and communicate.
- Environment variables: Kubernetes can import environment variables from older services when it creates new pods, enabling pod communication.
There are two options for Kubernetes external service discovery:
- Load balancer discovery: Kubernetes and the cloud provider together serve as load balancer, redirecting pod traffic.
- NodePort discovery: Kubernetes uses special ports of node IP addresses to expose NodePort services.
Kubernetes Service Discovery FAQs
How Does Service Discovery Work in Kubernetes?
Kubernetes service discovery is an abstraction that allows an application running on a set of Pods to be exposed as a network service. This enables a set of Pods to run using a single DNS name, and allows Kubernetes load balancing across them all. This way as Pods are dynamically created and destroyed on demand, frontends and backends can continue to function and connect.
The Kubernetes service is an abstraction that defines both a set of Pods based on logic and a policy for accessing the Pods, or a micro-service. A selector typically determines the set of Pods a Service targets.
As a Kubernetes service discovery example, consider a stateless backend for data-processing that is running with multiple fungible replicas. The specific Pods on the backend may change, but this isn’t important to the clients on the frontend, who neither need to track nor be aware of the backends themselves. Kubernetes service discovery is the abstraction that makes this separation possible.
What are Kubernetes Containers?
How does Kubernetes do service discovery? There are three schemes in Kubernetes for exposing services:
- ClusterIP. ClusterIP is the virtual IP address meant for pod communication within the cluster. ClusterIP services can expose their pods to the network. For example, Kubernetes exposes a database pod through a ClusterIP-based service to make it available to the web server pods.
- NodePort. Typically used for services with external consumers, NodePort is used to expose a service on the same port across all cluster nodes. An internal routing mechanism ensures that requests made via NodePort are forwarded automatically to the appropriate predetermined destination pods on each node.
- LoadBalancer. The load balancer component extends the NodePort service by adding Layer 4 (L4) and Layer 7 (L7) load balancers to a service, routing requests to the instances that can best handle them. Load balancers ensure that some containers don’t sit idle while others become overwhelmed with traffic. Clusters running in public cloud environments that support automated provisioning of software-defined load balancers often use this scheme.
When multiple services must share the same external endpoint or load balancer, an ingress controller may be indicated. An ingress controller provides secure socket layer (SSL) termination, load balancing, and name-based virtual hosting to manage external access to the services in a cluster.
There are three main Kubernetes service discovery methods: server-side discovery, client-side discovery, and DNS discovery.
Server-Side Service Discovery
Instance IPs can change without warning, making direct communication between services unpredictable. An intermediary such as a load balancer may be more reliable and promote better service discovery.
The load balancer or reverse proxy sits in front of a group of instances and constitutes a single service. From the perspective of the client, because the service discovery happens completely on the server-side, accessing the multi-instance service is just like accessing a single network endpoint.
The client makes an initial network request, triggering the server-side service discovery process. Kubernetes routes the request to a load balancer. However, not providing the right information may lead to making poor routing decisions; this is why the load balancer relies on the service registry to track and communicate with instances and relay their statuses.
Particularly in highly-loaded environments, the server-side service discovery has a few drawbacks. The load balancer component is a potential throughput bottleneck and a single point of failure, so a reasonable level of redundancy must be baked into the load balancing layer.
Client-side Service Discovery
By retaining the service registry and removing the load balancer from the equation in an attempt to improve service discovery, we arrive at client-side discovery. In practice, the most famous real-world example of client-side service discovery is the Netflix Eureka project.
These methods eliminate the load balancer as a single point of failure and thus reduce occasions for bottlenecking. The client:
- Retains the service registry
- Directly looks up the available service instance addresses in the service registry
- Fetches the service fleet, a complete list of IP addresses
- Determines which instances are viable
- Selects an optimal instance based on available load balancing strategies
- Sends a request to the preferred instance and awaits a response
The benefits of the client-side approach arise from the removal of the load balancer which ensures there is less chance of throughput bottleneck and no single point of failure, not to mention less equipment to cope with.
However, as with the server-side service discovery, client-side service discovery has some significant drawbacks. Client-side service discovery complicates the clients with extra logic, requiring integration code for every framework or programming language in the ecosystem and coupling clients with the service registry.
DNS Discovery
Finally, the concept of DNS service discovery exists. In this process, the client uses a DNS PTR record to reveal a list of instances and resolves to a domain name connected to a working instance.
However, some question whether this is complete service discovery. DNS creates either client-side or server-side solutions, more akin to the service registry. There are several issues with DNS discovery on the whole, including slow updating of DNS records which causes clients to wait on service ports and instance statuses even longer.
DNS is generally ill-suited for service discovery, including inside the Kubernetes ecosystem. This is why Kunernetes introduces one more IP address for every service rather than using round-robin DNS to list IP addresses of Pods. This is called clusterIP (not to be confused with the ClusterIP service type), a virtual IP.
Does VMware NSX Advanced Load Balancer Offer a Kubernetes Service Discovery Tool?
Appliance-based load balancing solutions are obsolete thanks to microservices-based modern application architectures. Kubernetes clusters deploying containerized applications need enterprise-class, scalable Kubernetes Ingress Services for monitoring/analytics service discovery, load balancing, local and global traffic management, and security.
VMware NSX Advanced Load Balancer’s advanced multi-cloud application services Kubernetes ingress controller offers enterprise-grade features, high levels of automation derived from machine learning, and enough observability to usher container-based applications into enterprise production environments.
Based on scalable, software-defined architecture, Vantage Kubernetes container services go far beyond what typical Kubernetes service controllers deliver. Expect a rich set of rollout and application maintenance tools as well as observability, security, and traffic management. VMware NSX Advanced Load Balancer’scentrally orchestrated, elastic proxy services fabric provides dynamic load balancing, analytics, security, micro-segmentation, and service discovery for containerized applications running in Kubernetes environments.
Find out more about VMware NSX Advanced Load Balancer’s Kubernetes service discovery here.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.