Kubernetes Load Balancer Definition
Kubernetes is an enterprise-level container orchestration system. In many non-container environments load balancing is relatively straightforward—for example, balancing between servers. However, load balancing between containers demands special handling.
A core strategy for maximizing availability and scalability, load balancing distributes network traffic among multiple backend services efficiently. A range of options for load balancing external traffic to pods exists in the Kubernetes context, each with its own benefits and tradeoffs.
Load distribution is the most basic type of load balancing in Kubernetes. At the dispatch level load distribution is easy to implement. Each of the two methods of load distribution that exist in Kubernetes operate through the kube-proxy feature. Services in Kubernetes use the virtual IPs which the kube-proxy feature manages.
The former default kube-proxy mode was userspace, which allocates the next available Kubernetes pod using round-robin load distribution on an IP list, and then rotates or otherwise permutes the list. Modern kube-proxy default mode, called iptables, enables sophisticated rule-based IP management. In iptables mode, random selection is the native method for load distribution. In this situation, an incoming request goes to one of a service’s pods that is randomly chosen.
However, neither of these techniques provides true load balancing. The Ingress load balancer for Kubernetes offers the most flexible and popular method, as well as cloud service-based load-balancing controllers and other tools for Ingress from service providers and other third parties.
Ingress operates using a controller which includes an Ingress resource and a daemon which applies its rules in a specialized Kubernetes pod. The controller has its own built-in capabilities, including sophisticated load balancing features. In an Ingress resource, you can also adjust for specific vendor or system requirements and load-balancing features by including more detailed load-balancing rules.
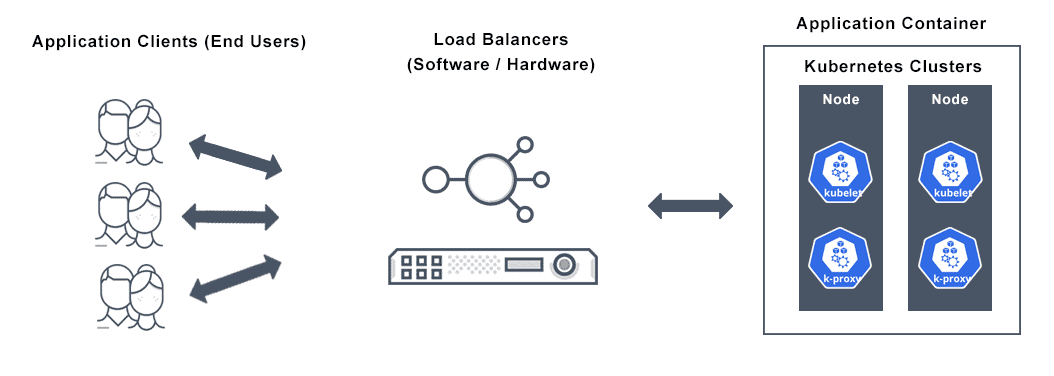
Kubernetes Load Balancer FAQs
What is Kubernetes Load Balancer?
Kubernetes is an extensible, portable, open-source platform for managing containerized services and workloads. Its large, rapidly growing ecosystem facilitates both automation and declarative configuration and Kubernetes support and tools are widely available.
In the internet’s earlier days, organizations experienced resource allocation issues as they ran applications on physical servers. One solution was to run separate applications on unique physical servers, but this is expensive and lacks ability to scale.
Virtualization was the next step which allowed organizations to run multiple Virtual Machines (VMs) on the CPU of a single physical server. Virtualization enables improved scalability, better utilization of resources, reduced hardware costs, and more. With virtualization, each VM runs all components on top of the virtualized hardware separately, including its own operating system.
Containers resemble VMs, except they are considered more lightweight, and can share the Operating System (OS) among the applications due to their relaxed isolation properties. However, like a VM, a container is portable across OS distributions and clouds, and amenable to being run by a system—such as Kubernetes.
In Kubernetes, a pod is a set of containers that are related by function. A set of related pods that have the same set of functions is a service. This allows Kubernetes to create and destroy pods automatically based on need, without additional input from the user, and pods are designed not to be persistent.
IP addresses for Kubernetes pods are not persistent because the system assigns each new pod a new IP address. Typically, therefore, direct communication between pods is impossible. However, services have their own relatively stable IP addresses which field requests from external resources. The service then dispatches the request to an available Kubernetes pod.
Kubernetes load balancing makes the most sense in the context of how Kubernetes organizes containers. Kubernetes does not view single containers or individual instances of a service, but rather sees containers in terms of the specific services or sets of services they perform or provide.
The Kubernetes pod, a set of containers, along with their shared volumes, is a basic, functional unit. Containers are typically closely related in terms of services and functions they provide.
Services are sets of Kubernetes pods that have the same set of functions. These Kubernetes services stand in for the individual pods as users access applications, and the Kubernetes scheduler ensures that you have the optimal number of pods running at all times by creating and deleting pods as needed. In other words, Kubernetes services are themselves the crudest form of load balancing traffic.
In Kubernetes the most basic type of load balancing is load distribution. Kubernetes uses two methods of load distribution. Both of them are easy to implement at the dispatch level and operate through the kube-proxy feature. Kube-proxy manages virtual IPs for services.
The default kube-proxy mode for rule-based IP management is iptables, and the iptables mode native method for load distribution is random selection. Previously, kube-proxy default mode was userspace, with its native method for load distribution being round-robin.
There are several cases when you might access services using the Kubernetes proxy:
- Allowing internal traffic
- Connecting directly to them directly from a computer
- Debugging services
- Displaying internal dashboards
However, you should not use this method for production services or to expose your service to the internet. This is because the kube proxy requires you to run kubectl as an authenticated user.
In any case, for true load balancing, Ingress offers the most popular method. Ingress operates using a controller with an Ingress resource and a daemon. The Ingress resource is a set of rules governing traffic. The daemon applies the rules inside a specialized Kubernetes pod. The Ingress controller has its own sophisticated capabilities and built-in features for load balancing and can be customized for specific vendors or systems.
A cloud service-based Kubernetes external load balancer may serve as an alternative to Ingress, although the capabilities of these tools are typically provider-dependent. External network load balancers may also lack granular access at the pod level.
There are many varieties of Ingress controllers, with various features, and a range of plugins for Ingress controllers, such as cert-managers that provision SSL certificates automatically.
How to Configure Load Balancer in Kubernetes?
Load balancing, a critical strategy for maximizing availability and scalability, is the process of distributing network traffic efficiently among multiple backend services. A number of Kubernetes load balancer strategies and algorithms for managing external traffic to pods exist. Each has its strengths and weaknesses.
Round Robin
In a round robin method, a sequence of eligible servers receive new connections in order. This algorithm is static, meaning it does not account for varying speeds or performance issues of individual servers, so a slow server and a better performing server will still receive an equal number of connections. For this reason, round robin load balancing is not always ideal for production traffic and is better for basic load testing.
Kube-proxy L4 Round Robin Load Balancing
The most basic default Kubernetes load balancing strategy in a typical Kubernetes cluster comes from the kube-proxy. The kube-proxy fields all requests that are sent to the Kubernetes service and routes them.
However, because the kube-proxy is actually a process rather than a proxy, it uses iptables rules to implement a virtual IP for the service, adding architecture and complexity to the routing. With each request, additional latency is introduced, and this problem grows with the number of services.
L7 Round Robin Load Balancing
In most cases, it is essential to route traffic directly to Kubernetes pods and bypass the kube-proxy altogether. Achieve this with an API Gateway for Kubernetes that uses a L7 proxy to manage requests among available Kubernetes pods.
The load balancer tracks the availability of pods with the Kubernetes Endpoints API. When it receives a request for a specific Kubernetes service, the Kubernetes load balancer sorts in order or round robins the request among relevant Kubernetes pods for the service.
Consistent Hashing/Ring Hash
In consistent hashing algorithms, the Kubernetes load balancer distributes new connections across the servers using a hash that is based on a specified key. Best for load balancing large numbers of cache servers with dynamic content, this algorithm inherently combines load balancing and persistence.
This algorithm is consistent because there is no need to recalculate the entire hash table each time a server is added or removed. Visualizing a circle or ring of nine servers in a pool or cache, adding a tenth server does not force a re-cache of all content. Instead, based on the outcome of the hash the nine servers already there send about 1/9, an even proportion, of their hits to the new server. Other connections are not disrupted.
The consistent or ring hash approach is used for sticky sessions in which the system ensures the same pod receives all requests from one client by setting a cookie. This method is also used for session affinity, which requires client IP address or some other piece of client state.
The consistent hashing approach is useful for shopping cart applications and other services that maintain per-client state. The need to synchronize states across pods is eliminated when the same clients are routed to the same pods. The likelihood of cache hit also increases as client data is cached on a given pod.
The weakness of ring hash is that client workloads may not be equal, so evenly distributing load between different backend servers can be more challenging. Furthermore, particularly at scale, the hash computation cost can add some latency to requests.
Google’s Maglev is a type of consistent hashing algorithm. Maglev has a costly downside for microservices, however: it is expensive to generate the lookup table when a node fails.
Fastest Response
Also called weighted response time, the fastest response method sends new connections to whichever server is currently offering the quickest response to new requests or connections. Fastest response is usually measured as time to first byte.
This method works well when the servers in the pool are processing short-lived connections or they contain varying capabilities. HTTP 404 errors are generally the sign of a server having problems, such as a lost connection to a data store. Frequent health checks can help mitigate against this kind of issue.
Fewest Servers
A fewest servers strategy determines the fewest number of servers required to satisfy current client load rather than distributing all requests across all servers. Servers deemed excess can either be powered down or de-provisioned, temporarily.
This kind of algorithm works by monitoring changes in response latency as the load adjusts based on server capacity. The Kubernetes load balancer sends connections to the first server in the pool until it is at capacity, and then sends new connections to the next available server. This algorithm is ideal where virtual machines incur a cost, such as in hosted environments.
Least Connections
The least connections dynamic Kubernetes load balancing algorithm distributes client requests to the application server with the least number of active connections at time of request. This algorithm takes active connection load into consideration, since an application server may be overloaded due to longer lived connections when application servers have similar specifications.
The weighted least connection algorithm builds on the least connection method. The administrator assigns a weight to each application server to account for their differing characteristics based on various criteria that demonstrate traffic-handling capability.
The least connections algorithm is generally adaptive to slower or unhealthy servers, yet offers equal distribution when all servers are healthy. This algorithm works well for both quick and long lived connections.
Resource Based/Least Load
Resource based or least load algorithms send new connections to the server with the lightest load, irrespective of the number of connections it has. For example, a load balancer receives one HTTP request requiring a 200-kB response and a second request that requires a 1-kB response. It sends the first to one server and the second to another. For new requests, the server then estimates based on old response times which server is more available—the one still streaming 200 kB or the one sending the 1-kB response to ensure a quick, small request does not get queued behind a long one. However, for non-HTTP traffic, this algorithm will default to the least connections method because the least load is HTTP-specific.
Does VMware NSX Advanced Load Balancer Offer a Kubernetes Load Balancer?
Microservices-based modern application architectures have rendered appliance-based load balancing solutions obsolete. Containerized applications deployed in Kubernetes clusters need scalable and enterprise-class Kubernetes Ingress Services for load balancing, monitoring/analytics service discovery, global and local traffic management, and security.
The VMware NSX Advanced Load Balancer Kubernetes ingress controller with multi-cloud application services offers high levels of automation based on machine learning, enterprise-grade features, and the observability that can usher container-based applications into enterprise production environments.
Based on a software-defined, scale-out architecture, VMware NSX Advanced Load Balancer provides container services for Kubernetes beyond typical Kubernetes service controllers, such as security, observability, traffic management, and a rich set of application maintenance and rollout tools. The centrally orchestrated, elastic proxy services fabric from VMware NSX Advanced Load Balancer provides analytics, dynamic load balancing, micro-segmentation, security, and service discovery for containerized applications running in Kubernetes environments.
The VMware NSX Advanced Load Balancer offers a cloud-native approach and delivers a scalable, enterprise-class container ingress to deploy and manage container-based applications in production environments accessing Kubernetes clusters. VMware NSX Advanced Load Balancer provides a container services fabric with a centralized control plane and distributed proxies:
- Controller: A central control, management and analytics plane that communicates with the Kubernetes control plane, deploys and manages the lifecycle of data plane proxies, configures services and aggregates telemetry analytics from the Service Engines.
- Service Engine: A service proxy providing ingress services such as load balancing, WAF, GSLB, IPAM/DNS in the dataplane and reporting real-time telemetry analytics to the Controller.
The VMware NSX Advanced Load Balancer extends L4-L7 services with automation, elasticity/autoscaling and continuous delivery onto Kubernetes Platform-as-a-Service (PaaS). Also, VMware NSX Advanced Load Balancer provides unprecedented visibility into Kubernetes applications showing service dependencies using application maps.
Find out more about VMware NSX Advanced Load Balancer’s Kubernetes ingress controller load balancer here.
For more on the actual implementation of load balancers, check out our Application Delivery How-To Videos.