Failover Definition
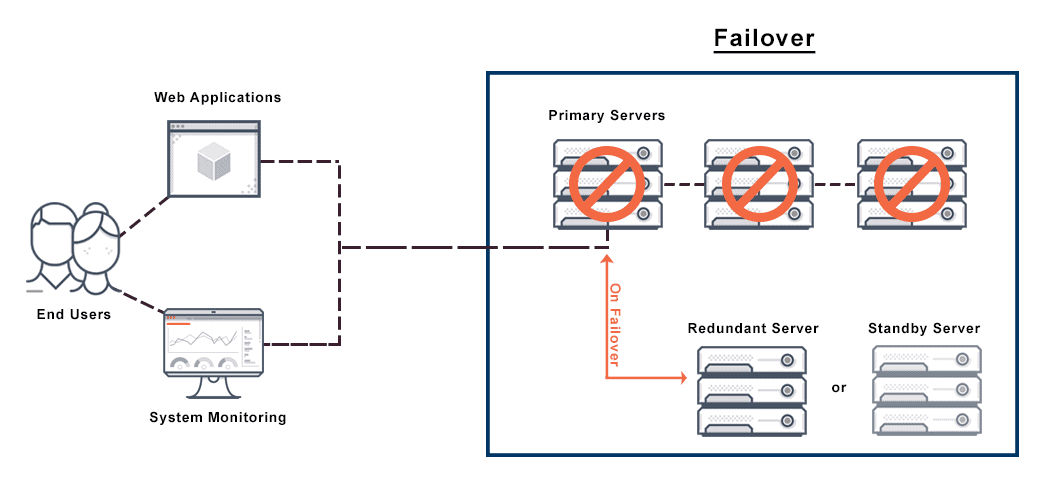
Failover is the ability to seamlessly and automatically switch to a reliable backup system. Either redundancy or moving into a standby operational mode when a primary system component fails should achieve failover and reduce or eliminate negative user impact.
A redundant or standby database server, system, or other hardware component, server, or network should be ready to replace any previously active version upon its abnormal termination or failure. Because failover is essential to disaster recovery, all standby computer server systems and other backup techniques must themselves be immune to failure.
Switchover is basically the same operation, but unlike failover it is not automatic and demands human intervention. Most computer systems are backed up by automatic failover solutions.
What is Failover?
For servers, failover automation includes heartbeat cables that connect a pair of servers. The secondary server merely rests as long as it perceives the pulse or heartbeat continues.
However, any change in the pulse it receives from the primary failover server will cause the secondary server to initiate its instances and take over the operations of the primary. It will also send a message to the data center or technician, requesting that the primary server be brought back online.
Some systems instead simply alert the data center or technician, requesting a manual change to the secondary server. This kind of system is called automated with manual approval configuration.
Storage area networks (SAN) enable multiple paths of connectivity among and between data storage systems and servers. This means fewer single points of failure, redundant or standby computer components, and multiple paths to help find a functional path in the event of component failure.
Virtualization uses a pseudomachine or virtual machine with host software to simulate a computer environment. This frees failover from dependency on physical computer server system hardware components.
What is a Failover Cluster?
A set of computer servers that together provide continuous availability (CA), fault tolerance (FT), or high availability (HA) is called a failover cluster. Failover clusters may use physical hardware only, or they may also include virtual machines (VMs).
In a failover cluster, the failover process is triggered if one of the servers goes down. This prevents downtime by instantly sending the workload from the failed component to another node in the cluster.
Providing either CA or HA for services and applications is the primary goal of a failover cluster. CA clusters, also called fault tolerant (FT) clusters, eliminate downtime when a primary system fails, allowing end users to keep using services and applications without any timeouts.
HA clusters, in contrast, offer automatic recovery, minimal downtime, and no data loss despite a potential brief interruption in service. Most failover cluster solutions include failover cluster manager tools that allow users to configure the process.
More generally, a cluster is two or more servers, or nodes, which are typically connected both via software and physically with cables. Some failover implementations include additional clustering technology such as load balancing, parallel or concurrent processing, and storage solutions.
Active-Active vs Active-Standby Configurations
The most common high availability (HA) configurations are active-active and active-standby or active-passive. These implementation techniques both improve reliability, but each achieves failover in a different way.
An active-active high availability cluster is usually composed of at least two nodes actively running the same type of service at the same time. The active-active cluster achieves load balancing—preventing any one node from overloading by distributing workloads across all the nodes more evenly. This also improves response and throughout times, because more nodes are available. The individual settings and configurations of the twin nodes should be identical to ensure redundancy and seamless operation of the HA cluster.
Load balancers assign clients to nodes in a cluster based on an algorithm, not randomly. For example, a round robin algorithm evenly distributes clients to servers based on when they connect.
In contrast, although there must be at least two nodes in an active-passive cluster, not all of them are active. Using a two node example again, with the first node in active mode, the second will be on standby or passive. This second node is the failover server, ready to function as a backup should the primary, active server stop functioning for any reason. Meanwhile, clients will only be connecting to the active server unless something goes wrong.
In the active-standby cluster, both servers must be configured with the very same settings, just as in the active-active cluster. This way, should the failover server need to take over, clients will not be able to perceive a difference in service.
Obviously, although the standby node is always running in an active-standby configuration, actual utilization of the standby node is nearly zero. Utilization of both nodes in an active-active configuration approaches 50-50, although each node is capable of handling the entire load. This means that if one node in an active-active configuration consistently handles more than half of the load, node failure can mean degraded performance.
With an active-active HA configuration, outage time during a failure is virtually zero because both paths are active. However, outage time has the potential to be greater with an active-passive configuration as the system needs time to switch from one node to the other.
What is a SQL Server Failover Cluster?
A SQL server failover cluster, also called a high-availability cluster, makes critical systems redundant. The SQL failover cluster eliminates any potential single point of failure by including shared data storage and multiple network connections via NAS (Network Attached Storage) or SANs.
The network connection called the heartbeat, discussed above, connects two servers. The heartbeat monitors each node in the SQL failover cluster environment constantly.
What is DHCP Failover?
A DHCP server relies on the standard Dynamic Host Configuration Protocol or DHCP to respond to client broadcast queries. This network server assigns and provides default gateways, IP addresses, and other network parameters to client devices automatically.
DHCP failover configuration involves using two or more DHCP servers to manage the same pool of addresses. This enables each of the DHCP servers to backup the other in case of network outages, and share the task of lease assignment for that pool at all times.
However, dialogue between failover partners is insecure, in that it is neither authenticated nor encrypted. In most organizations this is unnecessarily costly, because DHCP servers typically exist within the company’s secure intranet.
On the other hand, if your DHCP failover peers communicate across insecure networks, security is far more important. Configure local firewalls to prevent unauthorized users and devices from accessing the failover port. You can also protect the failover partnership from accidental or deliberate disruption by third parties by using VPN tunneling between the DHCP failover peers.
What is DNS Failover?
The Domain Name System (DNS) is the protocol that helps translate between IP addresses and hostnames that humans can read. DNS failover helps network services or websites stay accessible during an outage.
DNS failover creates a DNS record that includes two or more IP addresses or failover links for a single server. This way, you can redirect traffic to a live, redundant server and away from a failing server.
In contrast, failover hosting involves hosting a separate copy of your site at a different datacenter. This way no data is lost should one copy fail.
What is Application Server Failover?
Application server failover is simply a failover strategy that protects multiple servers that run applications. Ideally these application servers should themselves run on different servers, but they should at least have unique domain names. Application server load balancing is often part of a strategy following failover cluster best practices.
What is Failover Testing?
Failover testing is a method that validates failover capability in servers. In other words, it tests a system’s capacity to allocate sufficient resources toward recovery during a server failure.
Can the system move operations to backup systems and handle the necessary extra resources in the event of any kind of failure or abnormal termination? For example, failover and recovery testing will assess the system’s ability to power and manage multiple servers or an additional CPU when it reaches a performance threshold.
This threshold is most likely to be breached during critical failures—highlighting the relationship between security and resilience and failover testing.
Does VMware NSX Advanced Load Balancer offer a Cloud Failover Strategy?
A 3-node Controller cluster can help achieve high availability, provides node-level redundancy for the Controller and optimizes performance for CPU-intensive analytics functions. Find out more about Controller cluster high availability failover operation here.
For more on the actual implementation of load balancers, check out our Application Delivery How-To Videos.