Sizing Service Engines
Overview
VMware NSX Advanced Load Balancer publishes minimum and recommended resource requirements for VMware NSX Advanced Load Balancer Service Engines. This guide provides details on sizing. You can consult your Avi sales engineer for recommendations that are tailored to the exact requirements.
The Service Engines can be configured with 1 vCPU core and 2 GB RAM, and up to 64 vCPU cores and 256GB RAM.
Note: It is recommended for a ServiceEngine to have at least 4GB of memory when GeoDB is in use.
In write access mode, you an configure Service Engine resources for newly created SEs within the SE Group properties.
For the Service Engine in read or no orchestrator modes, the Service Engine resources are manually allocated to the SE virtual machine when it is being deployed.
VMware NSX Advanced Load Balancer Service Engine performance is determined by several factors, including hardware, Service Engine scaling, and the ciphers and certificates used. Performance can be broken down into the following primary benchmark metric:
-
Connections, Requests and SSL Transactions per second (CPS/ RPS/ TPS) — Primarily gated by the available CPU.
-
Bulk throughput — Dependent upon CPU, PPS and environment specific limitations.
-
Concurrent connections — Dependent on Service Engine memory.
This guide illustrates the expected real-world performance and discusses Service Engine internals on compute and memory usage.
CPU
VMware NSX Advanced Load Balancer supports x86 based processors including those from AMD and Intel. Leveraging AMD’s and Intel’s processors with AES-NI and similar enhancements steadily enhances VMware NSX Advanced Load Balancer’s performance with each successive generation of the processor.
CPU is a primary factor in SSL handshakes (TPS), throughput, compression, and WAF inspection.
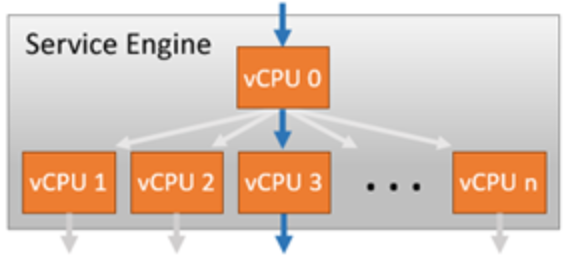
Performance increases linearly with CPU if CPU usage limit or environment limits are not hit. CPU is the primary constraint for both transactions per second and bulk throughput.
Within a Service Engine, one or more CPU cores will be given a dispatcher role. It will interface with NICs and distribute network flows across the other cores within the system, effectively load balancing the traffic to other CPU cores. Each core is then responsible for terminating TCP, SSL, and other processing determined by the virtual service configuration. The vCPU 0 in the above screenshot is acting as the dispatcher and can also handle some percentage of SSL traffic if it has the available capacity. By using a system of internally load balancing across CPU cores, VMware NSX Advanced Load Balancer can scale linearly across ever-increasing capacity.
Memory
Memory allocated to the Service Engine primarily impacts concurrent connections and HTTP caching. Doubling the memory will double the ability of the Service Engine to perform these tasks. The default is 2 GB memory, reserved within the hypervisor for VMware clouds. Refer to SE Memory Consumption for a verbose description of expected concurrent connections. Generally, SSL connections consume about twice as much memory as HTTP layer 7 connections, and four times as much memory as layer 4 with TCP proxy.
NIC
Throughput through a Service Engine can be a gating factor for the bulk throughput and sometimes for SSL-TPS. The throughput for an SE is highly dependent upon the platform.
Disk
The Service Engines may store logs locally before they are sent to the Controllers for indexing. Increasing the disk will increase the log retention on the SE. SSD is preferred over hard drives, as they can write the log data faster.
The recommended minimum size for storage is 15 GB, ((2 * RAM) + 5 GB) or 15 GB, whichever is greater. 15 GB is the default for SEs deployed in VMware clouds.
Disk Capacity for Logs
VMware NSX Advanced Load Balancer computes the disk capacity it can use for logs based on the following parameters:
-
Total disk capacity of the Service Engine
-
Number of Service Engine CPU cores
-
The main memory (RAM) of the Service Engine
-
Maximum storage on the disk not allocated for logs on the Service Engine (configurable via Service Engine runtime properties).
-
Minimum storage allocated for logs irrespective of Service Engine size.
You can calculate the capacity reserved for debug logs and client logs as follows:
-
Debug Logs capacity = (SE Total Disk * Maximum Storage not allocated for logs on SE)/ 100
-
Client Logs capacity = Total Disk – Debug Logs capacity
Adjustments to these values are done based on configured value for minimum storage allocated for logs and RAM of SE etc.
PPS
PPS is generally limited by hypervisors. Limitations are different for each hypervisor and version. PPS limits on Bare metal (no hypervisor) depend on the type of NIC used and how Receive Side Scaling (RSS) is leveraged.
RPS (HTTP Requests Per Second)
RPS is dependent on the CPU or the PPS limits. It indicates the performance of the CPU and the limit of PPS that the SE can push.
SSL Transactions Per Second
In addition to the hardware factors outlined above, TPS is dependent on the negotiated settings of the SSL session between the client and VMware NSX Advanced Load Balancer. The following are the points to consider for sizing based on SSL TPS:
-
VMware NSX Advanced Load Balancer supports both RSA and Elliptic Curve (EC) certificates. The type of certificate used, along with the cipher selected during negotiation, determines the CPU cost of establishing the session.
-
RSA 2k keys are computationally more expensive compared to EC. Avi Networks recommends you to use EC with PFS, which provides the best performance and the best possible security.
-
RSA certificates may still be used as a backup for clients that do not support current industry standards. As Avi supports both an EC certificate and an RSA certificate on the same virtual service, you can be gradually migrated to use EC certificates, with minimal user experience impact. Refer to RSA versus EC certificate priority for more on this.
-
VMware NSX Advanced Load Balancer’s default SSL profiles prioritize EC over RSA, and PFS over non-PFS.
-
EC using perfect forward secrecy (ECDHE) is about 15% more expensive than EC without PFS (ECDH).
-
SSL session reuse gives better SSL Performance for real world workloads.
Bulk Throughput
The maximum throughput for a virtual service depends on CPU as well as the NIC or hypervisor.
Using multiple NICs for client and server traffic can reduce the possibility of congestion or NIC saturation. The maximum packets per second for virtualized environments vary dramatically and will be the same limit regardless of the traffic being SSL or unencrypted HTTP.
Refer to Performance Datasheet numbers for throughput numbers. SSL throughput numbers are generated with standard ciphers mentioned in datasheet. Using more esoteric or expensive ciphers can have a negative impact on throughput. Similarly, using less secure ciphers, such as RC4-MD5, will provide better performance, but are also not recommended by security experts.
Generally, the TPS impact is negligible on the Service Engine’s CPU, if SSL re-encryption is required, since most of the CPU cost for establishing a new SSL session is on the server, not the client. For the bulk throughput, the impact to the Service Engine’s CPU will be double for this metric.
Concurrent Connections (also known as Open Connections)
While planning Service Engine sizing, the impact of concurrent connections should not be overlooked. Often administrators hear numbers of tens of millions of concurrent numbers achieved by a load balancer, so no further attention is paid to this metric. The concurrent benchmark numbers floating around are generally for layer 4 in a pass-through, or non-proxy mode. In other words, they are many orders of magnitude greater than what will be achieved. As a rough yet conservative estimate, assume 40kB of memory per SSL terminated connection in the real world. The amount of HTTP header buffering, caching, compression, and other features play a role in the final number. Refer to SE Memory Consumption for further details, including the methods for optimizing for greater concurrency.
Scale out capabilities across Service Engines
VMware NSX Advanced Load Balancer can also scale traffic across multiple Service Engines. Scale out allows linear scaling of workload. Scale-Out is primarily useful when CPU, memory and PPS become the limiting factor.
VMware NSX Advanced Load Balancer’s native auto-scale feature (L2 Scaleout) allows a virtual service to be scaled out across four Service Engines. Using ECMP scaleout (L3 Scaleout) a virtual service can be scaled out to multiple Service Engines with linear scale for workloads.
The following screenshot shows L2 Scaleout.
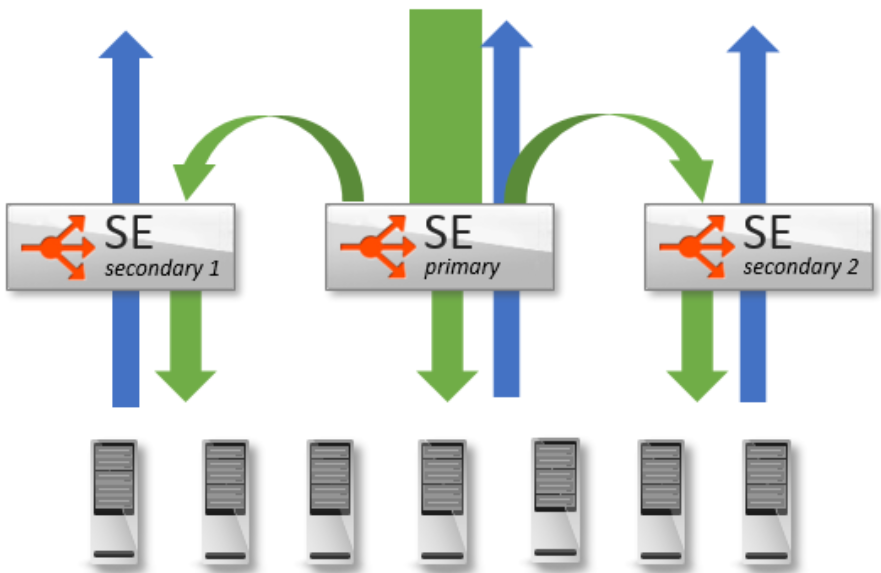
Refer to Autoscale Service Engines guide for further details on scaleout feature.
Service Engine Performance Datasheet
Refer to Performance Datasheet guide for more details on above limitations and sizing the Service Engine based on your applications behavior and load requirement.
The following are the points to be considered while sizing for different environments:
-
vCenter and NSX-T cloud
-
CPU reservation (configurable via se-group properties) is recommended.
-
RSS configuration for VMware based on the load requirement.
-
-
Baremetal and CSP (Linux Server Cloud) Deployment
-
A single Service Engine can scale up to 36 cores for linux server cloud (LSC) deployment for Baremetal and CSP.
-
PPS Limits on different clouds depend on either hypervisor or NIC used and how dispatcher cores and Receive Side Scaling (RSS) are configured. Refer to TSO, GRO, RSS, and Blocklist Feature on Avi Vantage guide for more information on recommended configuration and feature support.
-
-
SR-IOV and PCIe Passthrough are used in some environments to bypass the PPS limitations and provide line rate speeds. Refer to Ecosystem Support guide for more info on support for SR-IOV.
-
Sizing for public clouds should be decided based on the cloud limits and Service Engine performance on different clouds for different VM size.